
La bibliothèque Faker de Master Python pour générer et gérer de fausses données utilisateur. Idéal pour la protection de la vie privée et les tests logiciels, ce tutoriel couvre la création d’un programme polyvalent pour la génération de données réaliste, y compris la sauvegarde des options dans les formats CSV ou TXT.
Dans ce tutoriel, je vais vous montrer comment générer des fausses données utilisateur en Python. Le programme que nous sommes sur le point de faire à l’aide de l’outil Faker peut nous aider à garder les choses privées et anonymes en ligne. Vous pouvez l’utiliser pour inventer de faux détails qui agissent comme un bouclier contre les pirates potentiels, en gardant vos informations réelles en sécurité. Pour ceux qui connaissent le dark web, ce programme peut nous aider à nous inscrire à divers services sans entrer vos coordonnées correctes.
C’est également pratique pour les développeurs de logiciels qui ont besoin de données utilisateur pour les tests. Au lieu d’utiliser des données réelles de l’utilisateur, qui pourraient ne pas être sûres ou autorisées, ils peuvent utiliser les fausses données pour tester si leurs programmes fonctionnent correctement. C’est comme utiliser des données séparateurs pour s’assurer que tout fonctionne bien sans risquer d’informations réelles.
Comme mentionné précédemment, nous allons mettre en œuvre ce concept très cool en utilisant la bibliothèque Faker en Python. Le FakerLa bibliothèque en Python est un outil pour générer de fausses données. Avec Faker, vous pouvez générer un large éventail de fausses données, y compris des noms, des adresses, des numéros de téléphone, des adresses électroniques, des dates de naissance, des numéros de carte de crédit, et plus encore. Cela peut être particulièrement utile dans les scénarios où l’utilisation de données réelles n’est pas pratique ou pose des problèmes de confidentialité. N’hésitez pas à consulter la documentation ici.
Avant de pouvoir utiliser Faker, nous devons l’installer:
$ pip install FakerMaintenant, passons au codage. Nous allons implémenter ce programme en utilisant Python 3. Alors ouvrez un nouveau fichier Python, nommez-le de manière significative comme fake_data.py et suivez !
Comme d’habitude, nous commencerons par importer les bibliothèques et modules nécessaires :
#Importez les bibliothèques et modules nécessaires.
from faker import Faker
from faker.providers import internet
import csvLLe module csv de Python permet de lire et d’écrire facilement des fichiers CSV (Comma-Separated Values). Nous importons cela car après avoir généré nos données, nous demanderons à l’utilisateur de choisir s’il souhaite enregistrer les données ou non. S’ils le font, ils ont également la possibilité de sauvegarder les données dans un fichier CSV, TXT ou les deux.
Ensuite, nous créons une fonction pour générer les fausses données pour nous :
#Fonction pour générer des données utilisateur avec le nombre d'utilisateurs spécifié.
def generate_user_data(num_of_users):
#Créez une instance Faker.
fake = Faker()
#Ajoutez le fournisseur Internet pour générer des adresses e-mail et des adresses IP.
fake.add_provider(internet)
#Initialisez une liste vide pour stocker les données utilisateur.
user_data = []
#Boucle pour générer des données pour le nombre spécifié d'utilisateurs.
for _ in range(num_of_users):
#Créez un dictionnaire représentant un utilisateur avec divers attributs.
user = {
'Name': fake.name(),
'Email': fake.free_email(),
'Phone Number': fake.phone_number(),
'Birthdate': fake.date_of_birth(),
'Address': fake.address(),
'City': fake.city(),
'Country': fake.country(),
'ZIP Code': fake.zipcode(),
'Job Title': fake.job(),
'Company': fake.company(),
'IP Address': fake.ipv4_private(),
'Credit Card Number': fake.credit_card_number(),
'Username': fake.user_name(),
'Website': fake.url(),
'SSN': fake.ssn()
}
#Ajoutez le dictionnaire de données utilisateur à la liste user_data.
user_data.append(user)
#Renvoie la liste des données utilisateur générées.
return user_dataDans cette fonction, en utilisant Faker, nous avons mis en place une fonctionnalité pour générer de fausses données pour nous. Les données à générer comprennent le nom, le courrier électronique, le numéro de téléphone, etc. Les données générées seront écrites dans un fichier CSV ou TXT. Selon le choix de l’utilisateur. Maintenant, implémentons la fonctionnalité pour sauvegarder les données dans un csv Dossier:
#Fonction pour enregistrer les données utilisateur dans un fichier CSV.
def save_to_csv(data, filename):
#Obtenez les clés (noms de colonnes) du premier dictionnaire de la liste de données.
keys = data[0].keys()
#Ouvrez le fichier CSV pour l'écriture.
with open(filename, 'w', newline='') as output_file:
#Créez un rédacteur CSV avec les noms de colonnes spécifiés.
writer = csv.DictWriter(output_file, fieldnames=keys)
#Écrivez la ligne d'en-tête dans le fichier CSV.
writer.writeheader()
#Parcourez chaque dictionnaire utilisateur et écrivez une ligne dans le fichier CSV.
for user in data:
writer.writerow(user)
#Imprimez un message de réussite indiquant que les données ont été enregistrées dans le fichier.
print(f'[+] Data saved to {filename} successfully.')De même, nous créerons une fonction pour sauvegarder les données dans un fichier texte (si c’est ce que l’utilisateur préfère):
#Fonction pour enregistrer les données utilisateur dans un fichier texte.
def save_to_text(data, filename):
#Ouvrez le fichier texte pour l'écriture.
with open(filename, 'w') as output_file:
#Parcourez chaque dictionnaire utilisateur.
for user in data:
#Parcourez les paires clé-valeur dans le dictionnaire utilisateur et écrivez dans le fichier texte.
for key, value in user.items():
output_file.write(f"{key}: {value}\n")
#Ajoutez une nouvelle ligne entre les utilisateurs dans le fichier texte.
output_file.write('\n')
#Imprimez un message de réussite indiquant que les données ont été enregistrées dans le fichier.
print(f'[+] Data saved to {filename} successfully.')Pour la lisibilité, nous implémentons une fonction d’impression verticale des données générées. En effet, par défaut, lorsque nous exécutons le code, si l’utilisateur veut juste voir les données et ne pas les sauvegarder, les données générées sont imprimées dans un key-value pairse formant horizontalement. La lecture des données sous cette forme peut devenir un peu écrasante. C’est donc une meilleure pratique pour l’imprimer verticalement. Nous l’avons également fait dans la fonction save_to_text(). Nous n’avons pas eu besoin de le faire pour save_to_csv() parce que les fichiers CSV sont séparés par des virgules:
#Fonction pour imprimer les données utilisateur verticalement.
def print_data_vertically(data):
#Parcourez chaque dictionnaire utilisateur de la liste de données.
for user in data:
#Parcourez les paires clé-valeur dans le dictionnaire utilisateur et imprimez verticalement.
for key, value in user.items():
print(f"{key}: {value}")
#Ajoutez une nouvelle ligne entre les utilisateurs.
print()Enfin, nous implémentons la fonctionnalité pour accepter l’entrée de l’utilisateur:
#Obtenez le nombre d'utilisateurs à partir de l'entrée de l'utilisateur.
number_of_users = int(input("[!] Enter the number of users to generate: "))
#Générez des données utilisateur en utilisant le nombre d'utilisateurs spécifié.
user_data = generate_user_data(number_of_users)
#Demandez à l'utilisateur s'il souhaite enregistrer les données dans un fichier.
save_option = input("[?] Do you want to save the data to a file? (yes/no): ").lower()
#Si l'utilisateur choisit de sauvegarder les données.
if save_option == 'yes':
#Demandez à l'utilisateur le type de fichier (CSV, TXT ou les deux).
file_type = input("[!] Enter file type (csv/txt/both): ").lower()
#Enregistrez au format CSV si l'utilisateur a choisi CSV ou les deux.
if file_type == 'csv' or file_type == 'both':
#Demandez à l'utilisateur le nom du fichier CSV.
custom_filename_csv = input("[!] Enter the CSV filename (without extension): ")
#Concaténez le nom de fichier avec l'extension .csv.
filename_csv = f"{custom_filename_csv}.csv"
#Appelez la fonction save_to_csv pour enregistrer les données dans le fichier CSV.
save_to_csv(user_data, filename_csv)
#Enregistrez au format TXT si l'utilisateur a choisi TXT ou les deux.
if file_type == 'txt' or file_type == 'both':
#Demandez à l'utilisateur le nom du fichier TXT.
custom_filename_txt = input("[!] Enter the TXT filename (without extension): ")
#Concaténez le nom de fichier avec l'extension .txt.
filename_txt = f"{custom_filename_txt}.txt"
#Appelez la fonction save_to_text pour enregistrer les données dans le fichier texte.
save_to_text(user_data, filename_txt)
#Si l'utilisateur a entré un type de fichier non valide.
if file_type not in ['csv', 'txt', 'both']:
#Imprimez un message d'erreur indiquant que le type de fichier n'est pas valide.
print("[-] Invalid file type. Data not saved.")
#Si l'utilisateur a choisi de ne pas enregistrer les données, imprimez-les verticalement.
else:
#Appelez la fonction print_data_vertically pour imprimer les données verticalement.
print_data_vertically(user_data)Cette partie du code commence par inviter l’utilisateur à entrer le nombre d’utilisateurs souhaité pour générer puis procéder à la génération de données utilisateur en conséquence. Par la suite, il demande si l’utilisateur souhaite sauvegarder les données générées, fournissant des options pour les formats CSV et TXT permettant la personnalisation des noms de fichiers. Le script appelle de manière appropriée les fonctions pour sauvegarder les données en fonction des préférences de l’utilisateur ou, si l’utilisateur choisit de ne pas les enregistrer, imprime les données générées verticalement pour l’affichage (comme mentionné précédemment).
Voilà, vous l’avez. Nous venons d’écrire un programme qui peut être utilisé pour générer de fausses données utilisateur. Examinons notre code pour voir comment il fonctionne. Veuillez garder à l’esprit que je choisirai l’option «à la fois» aux fins des tests lorsque le type de fichier que je souhaite vous demander. N’hésitez pas à tester toutes les options disponibles. En outre, les fichiers générés seront sauvegardés dans votre répertoire de travail actuel.
Exécuter le code:
$ python fake_data.py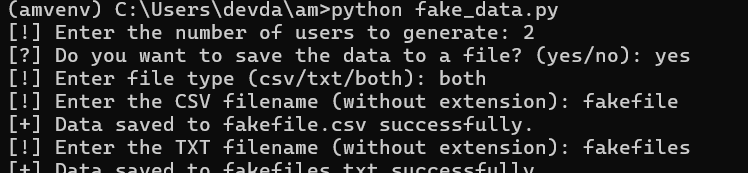
Lorsque j’ouvre le fichier CSV (avec MS Excel):

Une chose à noter est qu’Excel tend à réduire les grands nombres à leurs formes scientifiques (comme on le voit dans la colonne «numéro de carte de crédit»). Pour voir la valeur réelle (étendue), double-cliquez simplement sur la valeur que vous essayez de voir.
Voyons à quoi ressemblent nos données générées dans le format texte:

Enfin, voyons à quoi ressemblent les données quand l’utilisateur les voit et ne les sauve pas.

Voilà, vous l’avez. Similaire au format texte. C’est grâce à la fonction print_data_vertically().
Avec cela, nous sommes arrivés à la fin de ce tutoriel. Comme toujours, n’hésitez pas à consulter la documentation Faker pour en savoir plus sur la bibliothèque Faker. Vous pouvez rechercher plus de variables pour étendre la génération de données.
En conclusion, la maîtrise de l’art de la production de fausses données permet non seulement aux utilisateurs de renforcer efficacement leur vie privée en ligne, mais s’avère également inestimable dans le domaine des tests de logiciels. En comprenant et en exploitant les capacités d’outils tels que la Bibliothèque Faker, nous pouvons naviguer dans le paysage numérique avec un sentiment accru de sécurité tout en contribuant au développement et à la fortification de logiciels robustes et soucieux de la vie privée. Embrassez la polyvalence des fausses données – un outil à double usage qui protège les informations personnelles et propulse l’innovation dans le paysage toujours en évolution de la technologie. Restez curieux, restez en sécurité, et joyeux de codage.